options.async = true: you get back a job ID, and you poll until done.
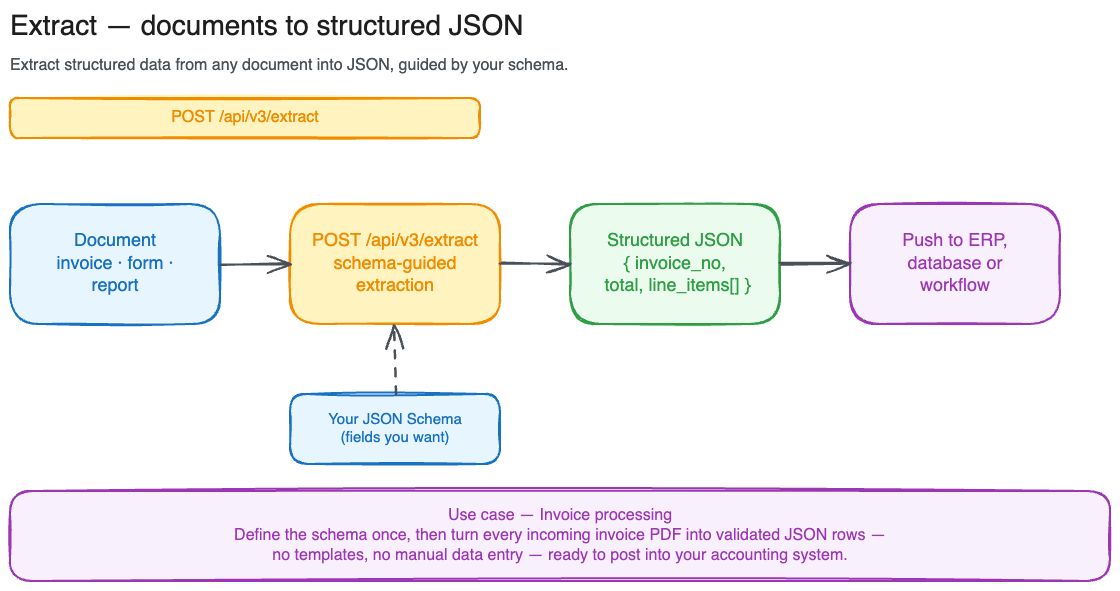
When to use Extract
| Input | Output | Best for | |
|---|---|---|---|
| Search | Query string | Ranked text chunks | Finding passages across many documents |
| Parse | Document file | Markdown text | Converting a document to clean text |
| Extract | Document + JSON Schema | Structured object | Pulling typed fields from forms, invoices, contracts |
Sync extraction (small documents)
Sync mode handles documents up to 20 MB, 15 pages and returns the full result in one response.multipart/form-data instead of a URL:
schema arrives as a JSON-encoded string and is decoded server-side.
Async extraction (large documents)
For documents up to 100 MB, 1000 pages, setoptions.async = true. The API returns a 202 Accepted immediately with a job ID.
GET /api/v3/extract/{job_id} until status is completed or failed. Recommended cadence: 1 s for the first 10 s, then 5 s, capped at 30 s.
Reading the response
Sync and async responses share the same shape:result.data is one entry per page, each shaped like your schema. Fields that weren’t found on a given page are null. When the document has more than 15 pages, result.data is paginated: request additional pages with ?page=N on the GET /api/v3/extract/{job_id} endpoint.
Common errors
| Status | Cause |
|---|---|
400 | Missing document/file, unsupported format, or page limit exceeded |
401 | Missing or invalid API key |
404 | Extract job not found |
413 | File exceeds the size limit (20 MB sync, 100 MB async) |
422 | JSON Schema is malformed, uses unsupported features, or exceeds limits |
429 | Rate limit exceeded (6 requests/second per tenant) |
503 | Parsing backend is overloaded. Retry later |