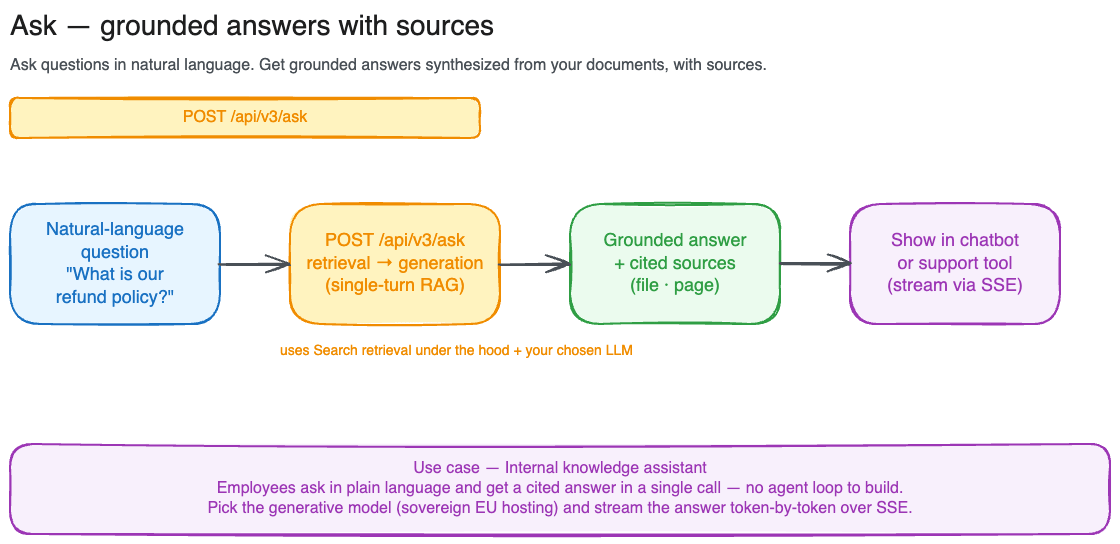
Your first question
Reading the response
The response has two fields:answer: the LLM-generated answer, grounded in the retrieved passages.results: the ranked chunks used as context, in the same shape as a Search result (chunk_id,content,score,scores,source,workspace). Use these to show citations or let users open the source document.
Scoping to a subset of documents
Ask uses the same scoping rules as Search. Passworkspace_id and/or tag_id to narrow the corpus, or file_id to target specific files. file_id is mutually exclusive with workspace_id and tag_id.
max_results (default 10, range 1 to 50) controls how many passages are retrieved and fed to the model as context. More context can improve answer quality on broad questions, at the cost of latency.
Choosing a model
Two models are supported. Any other value is rejected with a422.
Streaming the answer
For chat-style UIs where you want to show the answer as it’s written, setstream: true. The response is a stream of Server-Sent Events instead of a single JSON body:
done event.